The Evolution Of GenAI Applications -
From Single LLM Call to Agentic AI
2025-04-16
Agenda of this Presentation in a Picture
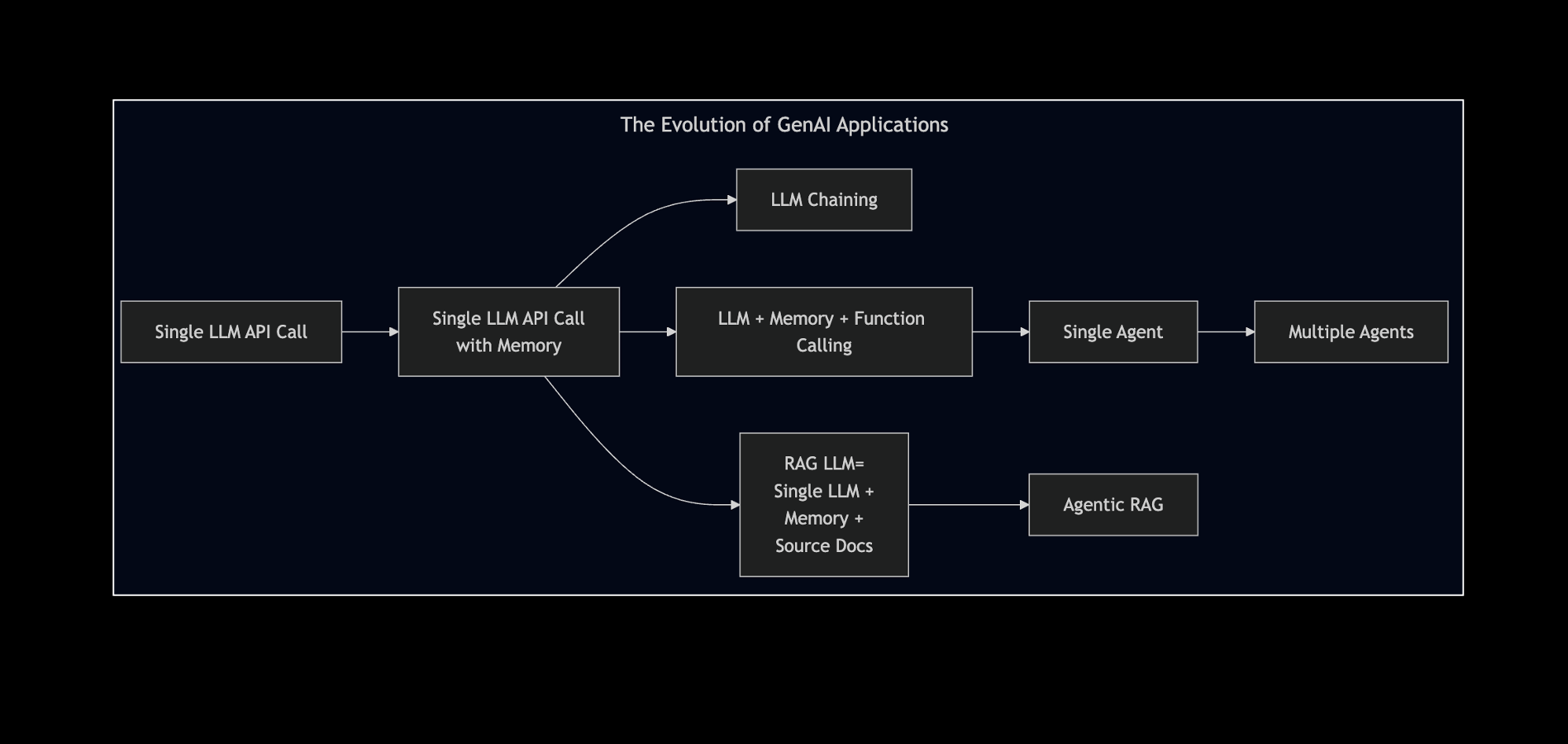
Agenda
LLM Application with a Single LLM API Call
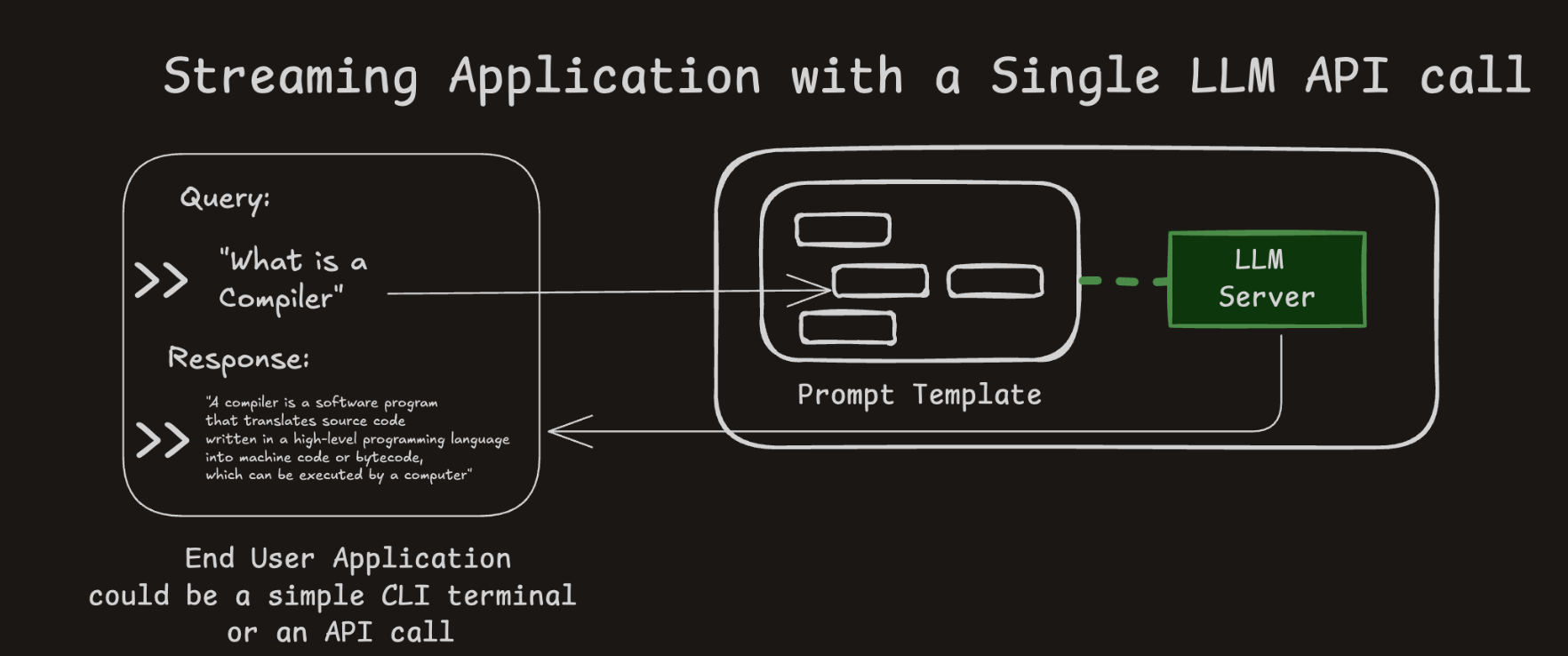
- 1 LLM call per response
- Your query fits into a set prompt of the selected LLM model
Chatbot Application with a Single LLM API Call

- Adds contextual history to prompts, enhancing conversational memory.
- Still makes only one LLM call per message, but simulates continuity.
- Chat history is stitched manually into each prompt (stateless memory).
Image Inspiration: Jay Alammar’s Hands-on Large Language Models
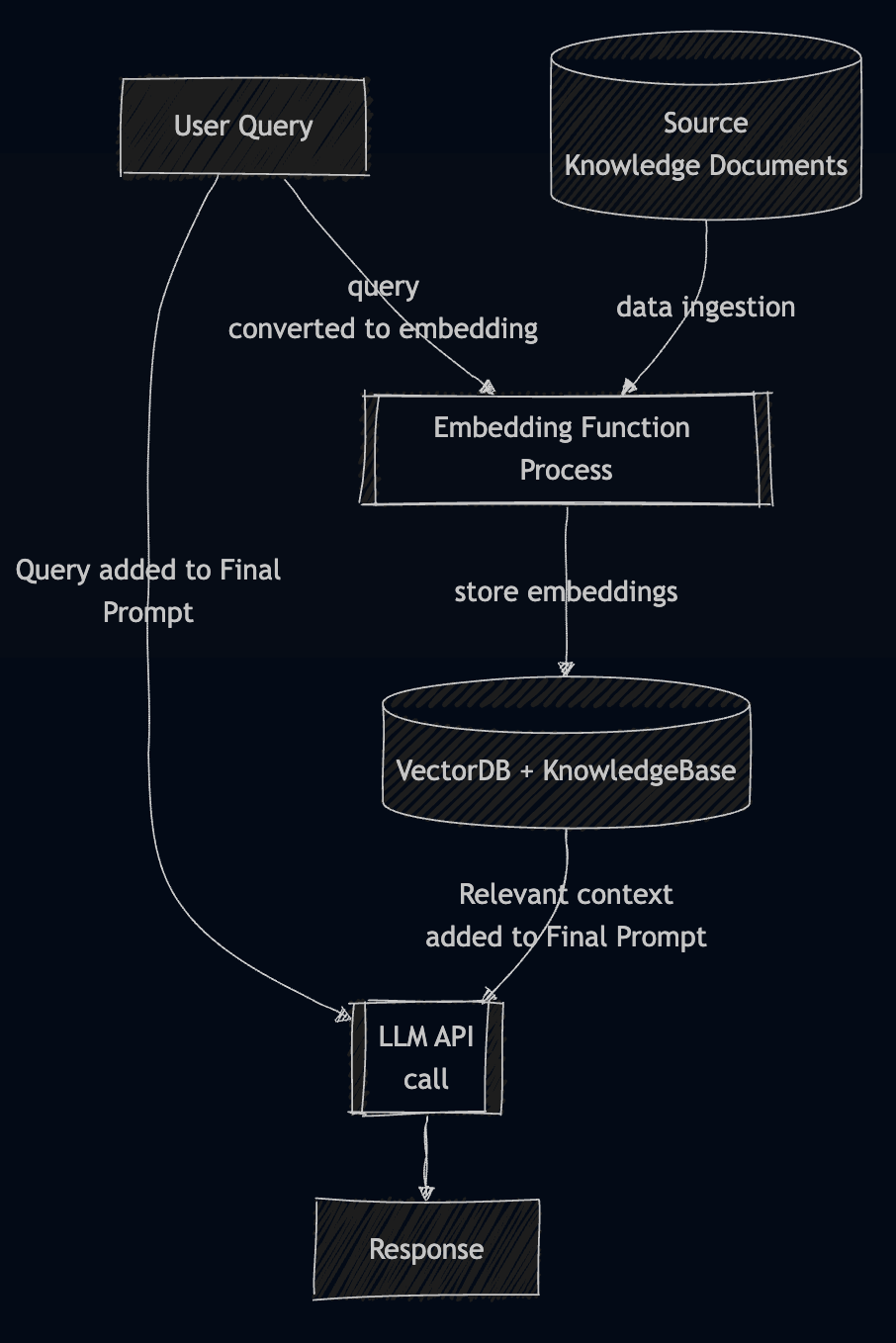
RAG Chatbot (1/2)
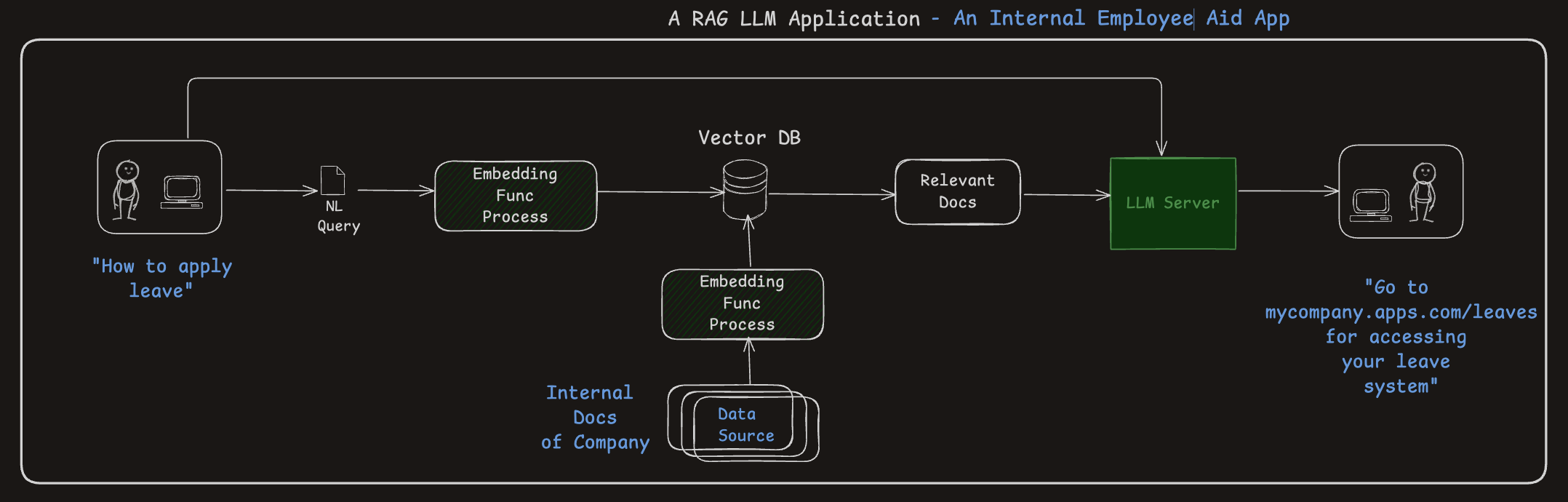
- Embeddings + vector search = more accurate and context-aware responses.
- A powerful architecture for grounding answers in known data sources (better for avoiding hallucinations)
RAG Chatbot (2/2)
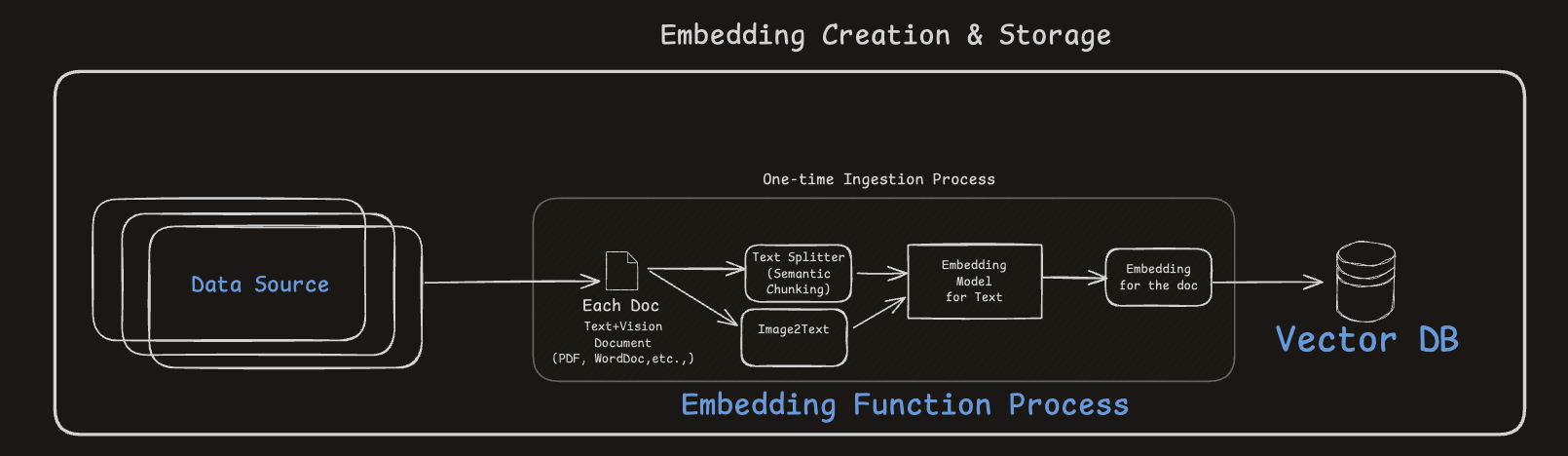
- Converts raw documents (text/images) into semantically rich embeddings.
- Embeddings are indexed into a Vector DB for fast similarity search.
- Document chunking improves search granularity and retrieval accuracy.
- Better your chunking, better is the accuracy of answers
- Better the embeddings in encoding meaning, better is the accuracy of answers
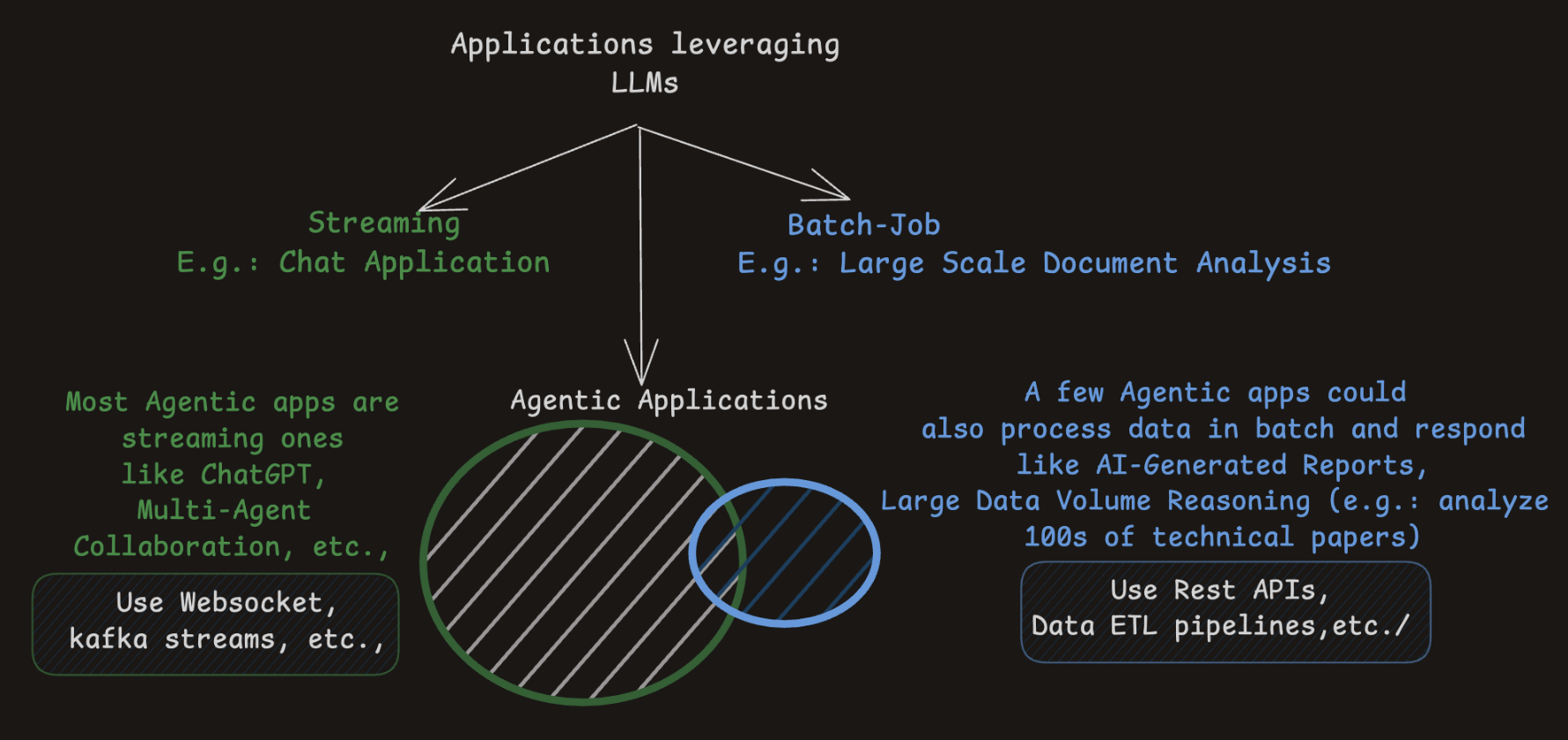
LLM RAG vs Agentic RAG
- Jumping a few steps here but we will circle back to Agentic RAG
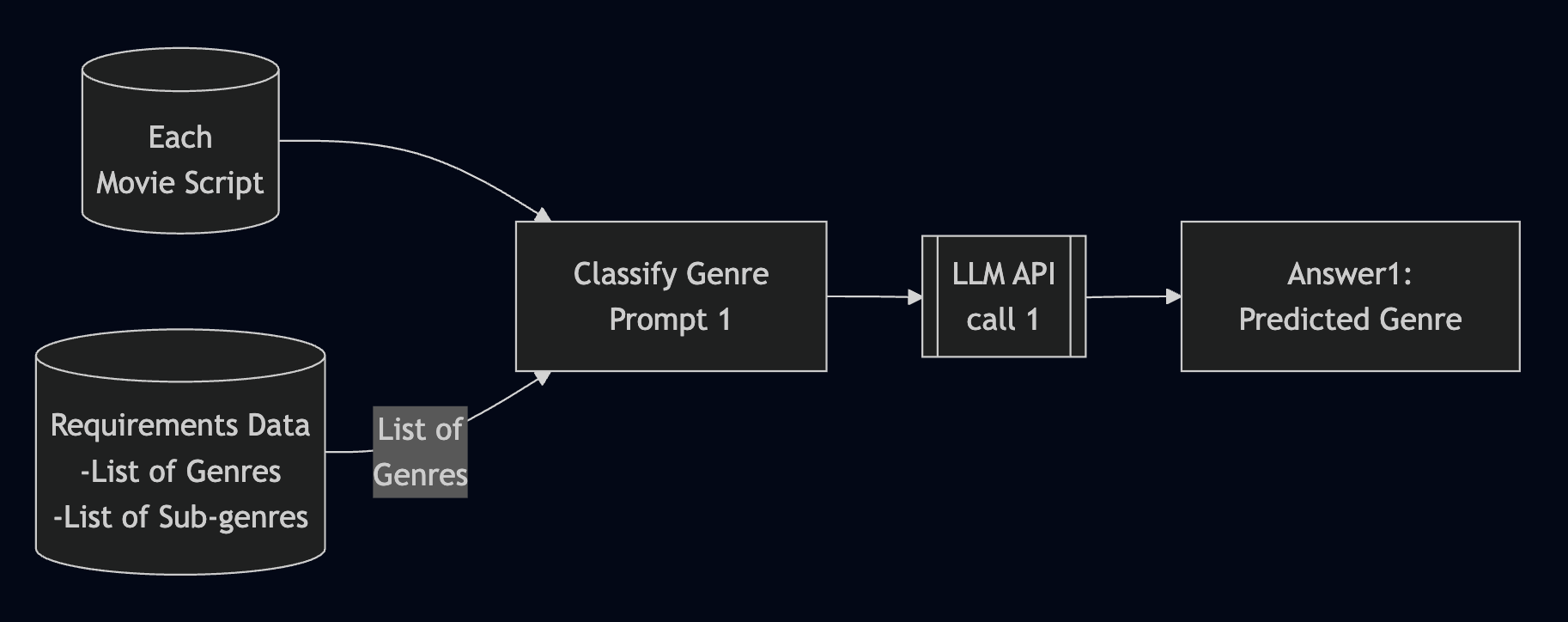
A Typical Batch Processing LLM Application
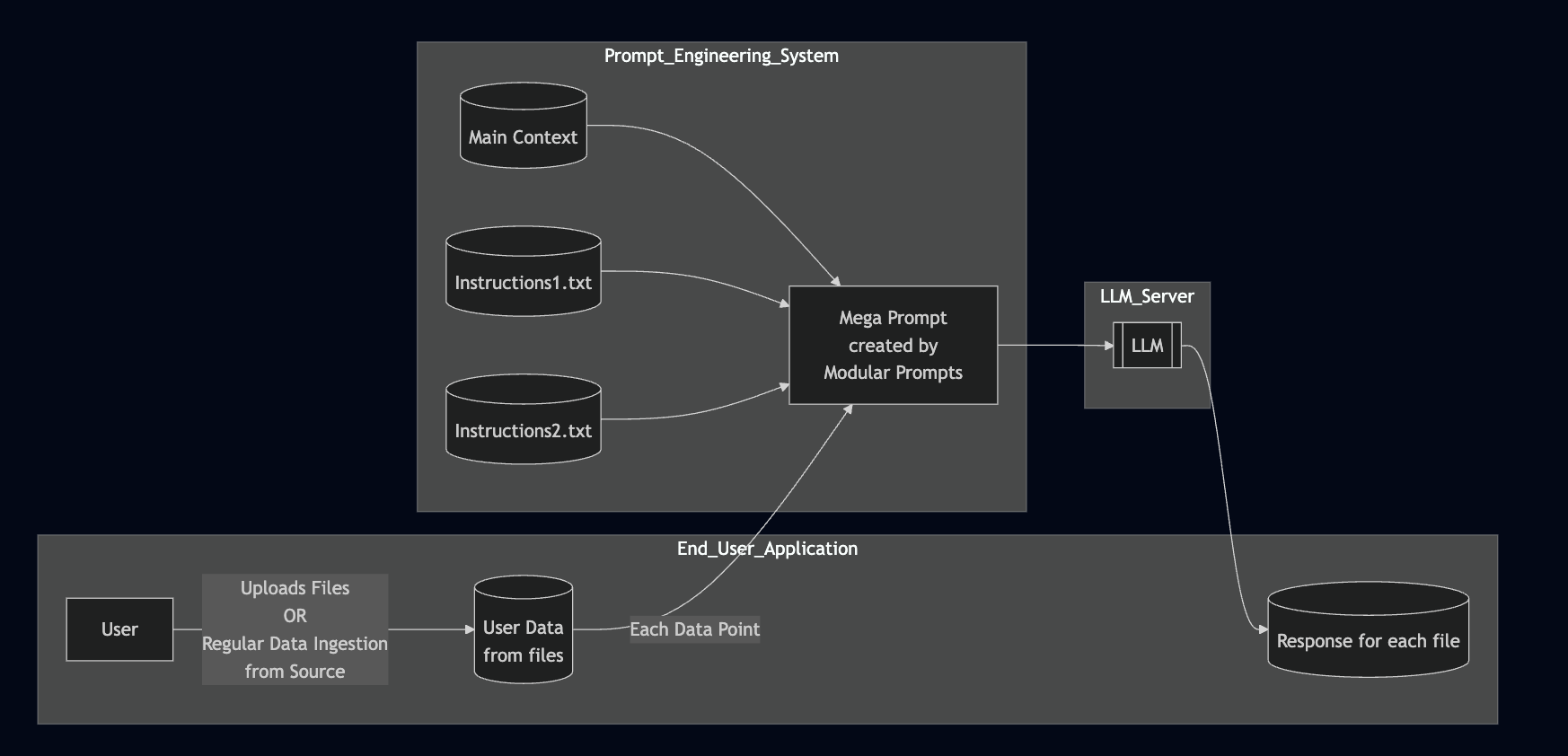
- Context or instructions can be dynamically adjusted via prompt templating
- External context can be modularized to avoid long, hard-coded prompts
- All data in the same batch use the same prompt template
A Text Classification Application
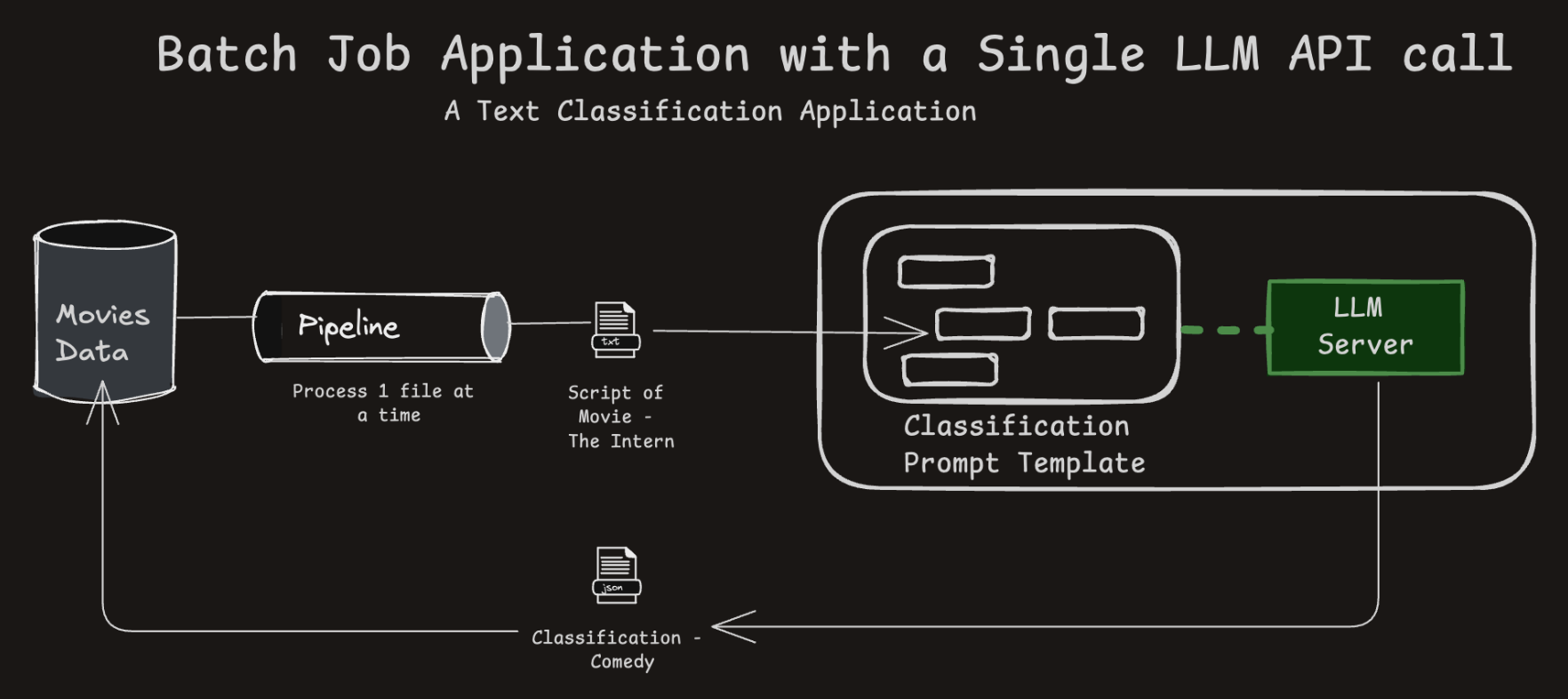
- Processes multiple data items (e.g., documents) using the same LLM pipeline.
- Scales LLM use to bulk operations like NER tagging or classification.
A Chained LLM Application (1/2)
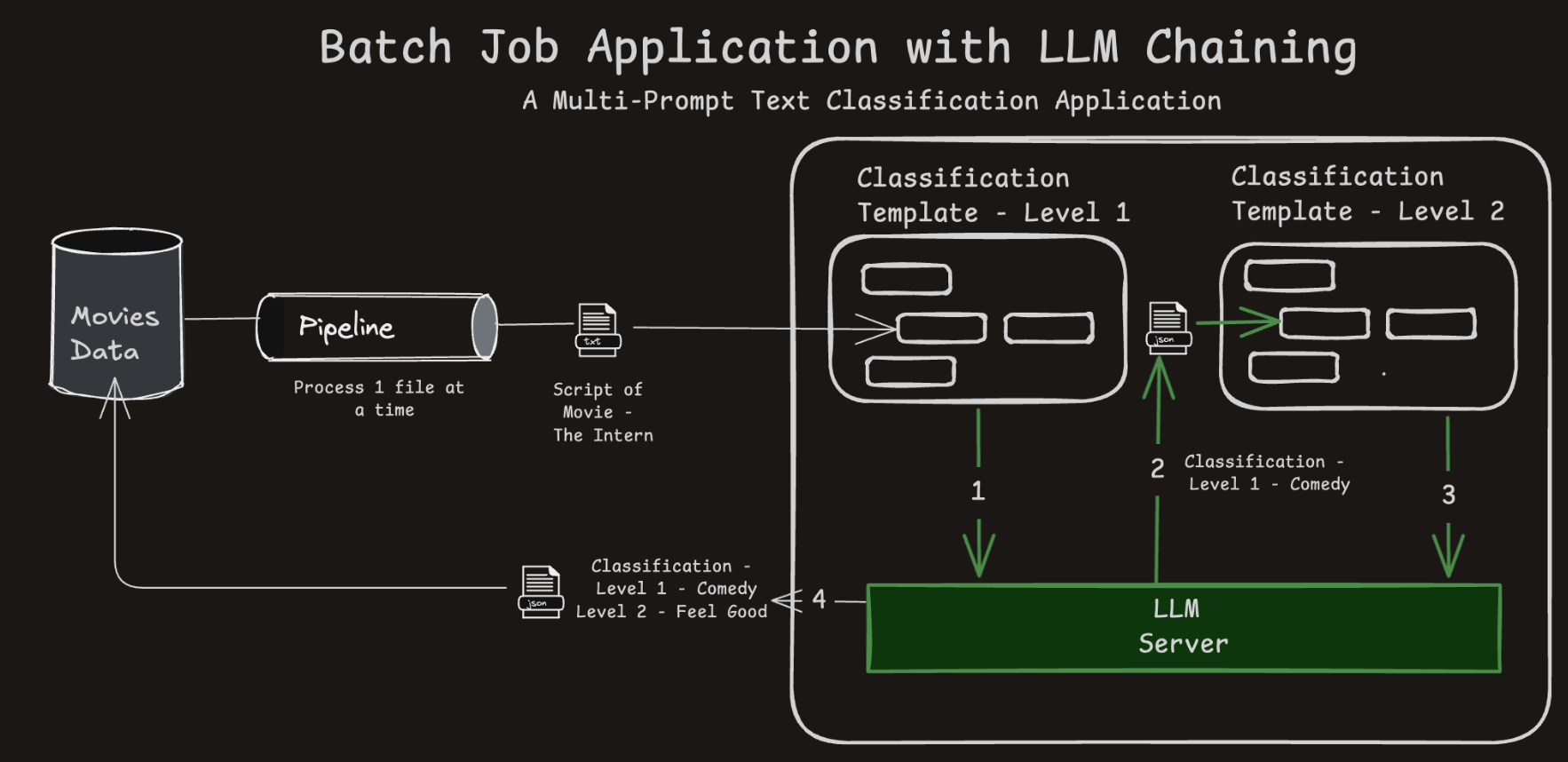
- Uses chained prompts where the output of one LLM call feeds into another.
- Demonstrates how logic can be split into reusable, modular steps.
A Chained LLM Application (2/2)

How Prompt Engineering Started
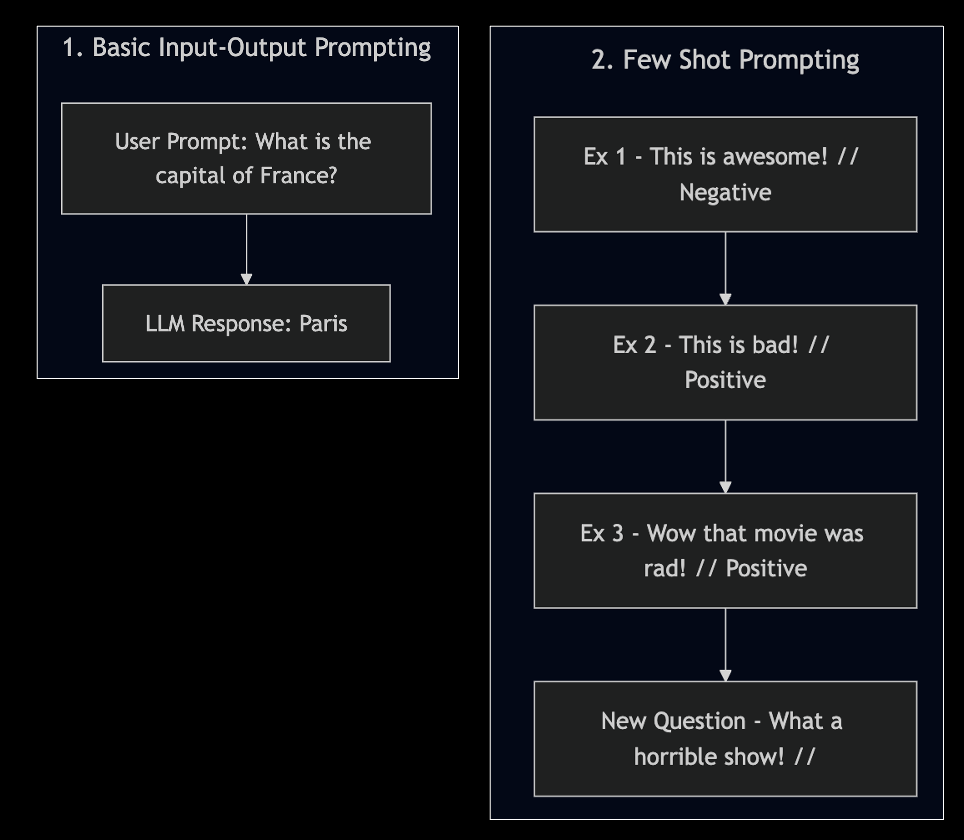
- As the context window of LLMs improved,
- Input-Output Prompting evolved into Few Shot Prompting for better results
Reasoning Prompts - CoT & ReAct Prompts in Few Shot Style
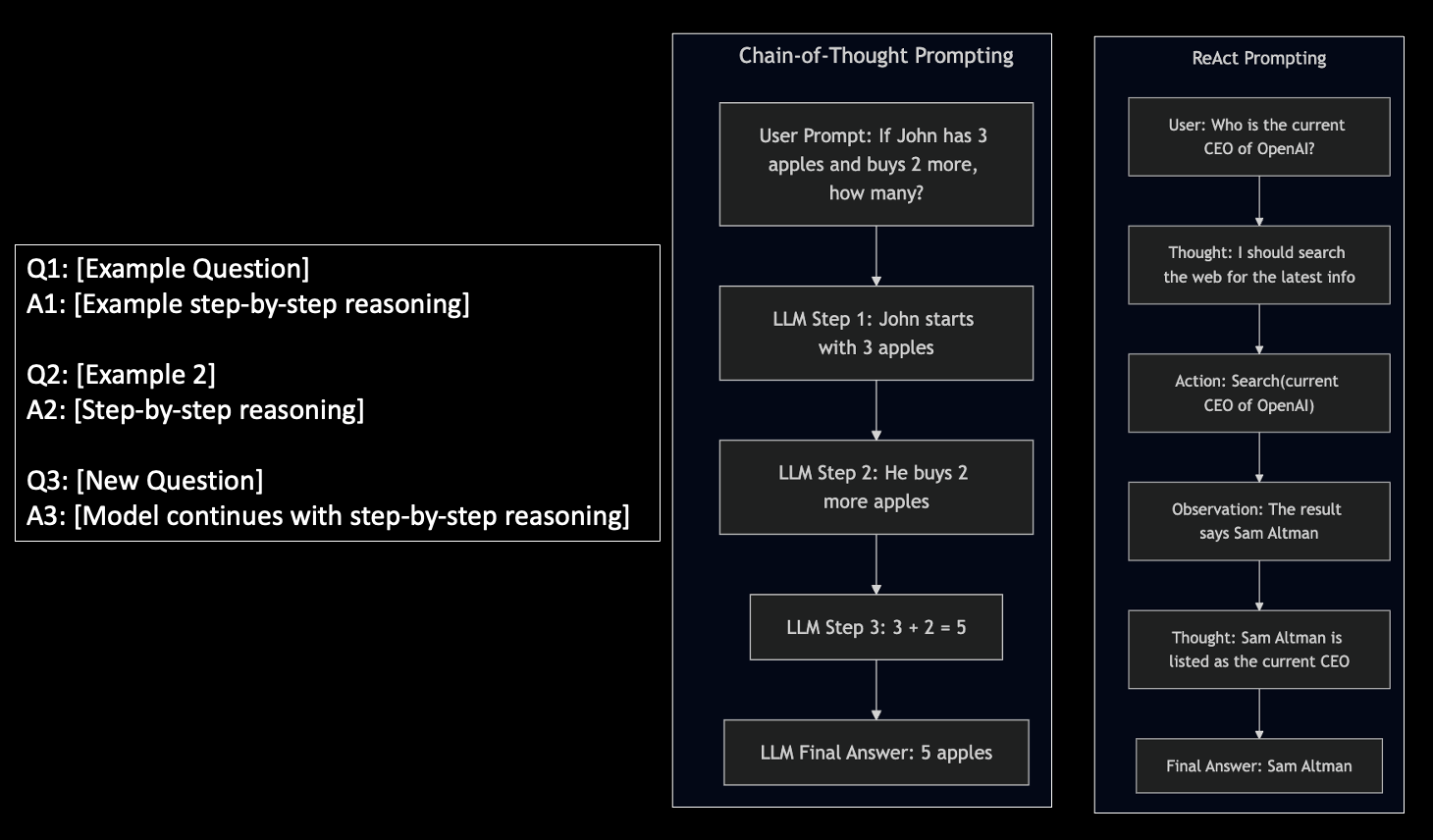
- Explaining LLMs to think/reason step by step with examples
Reasoning Prompts - CoT & ReAct Techniques During Inference
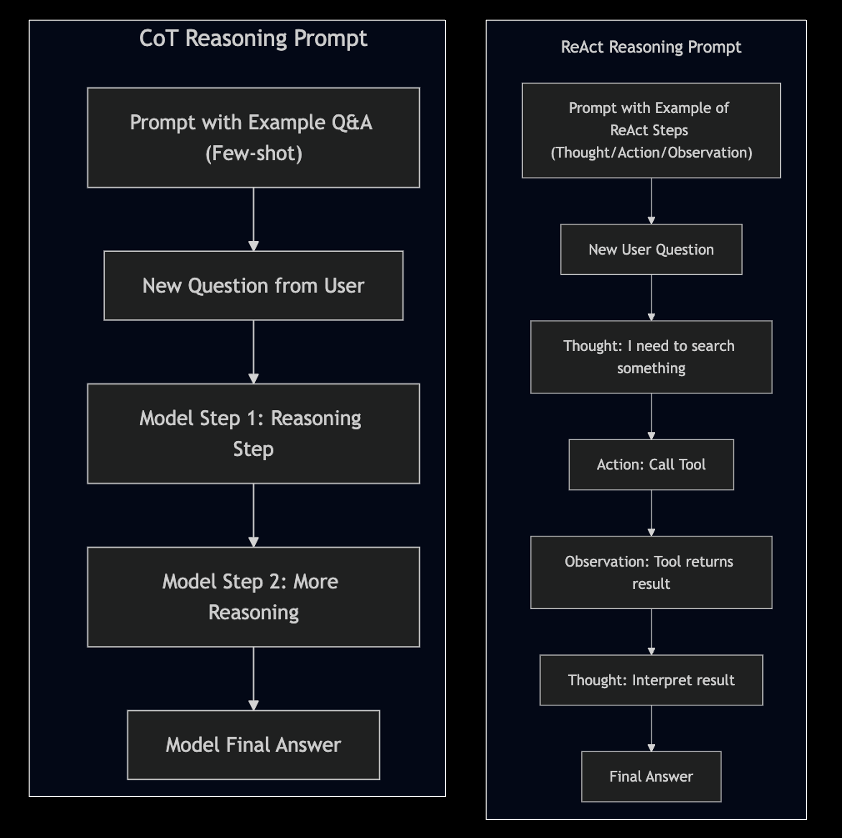
- Explaining LLMs to think/reason step by step with examples
Structured Function Calling - A Robust Alternative to ReAct

Large Reasoning Models
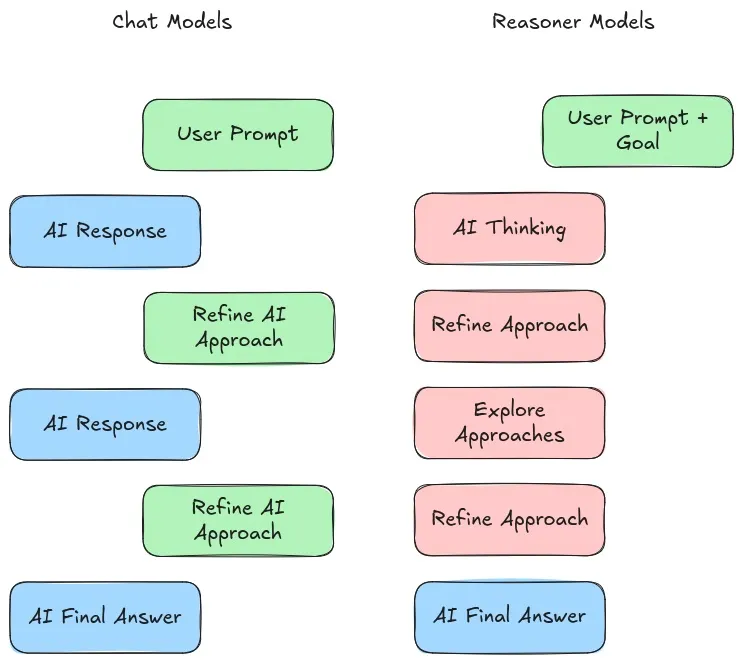
- LLMs: input → LLM → output statement
- LRMs: input → LRM → Keeps Planning Steps → Finally, output statement
- LRMs are generating text similar LLMs but they are trained to “think before acting”
- E.g.: OpenAI o1, DeepSeek R1
- LRMs think during inference, hence needing more “test-time compute”
Source 1: Aishwarya Naresh’s Substack
Source 2: A Visual Guide to Reasoning LLMs
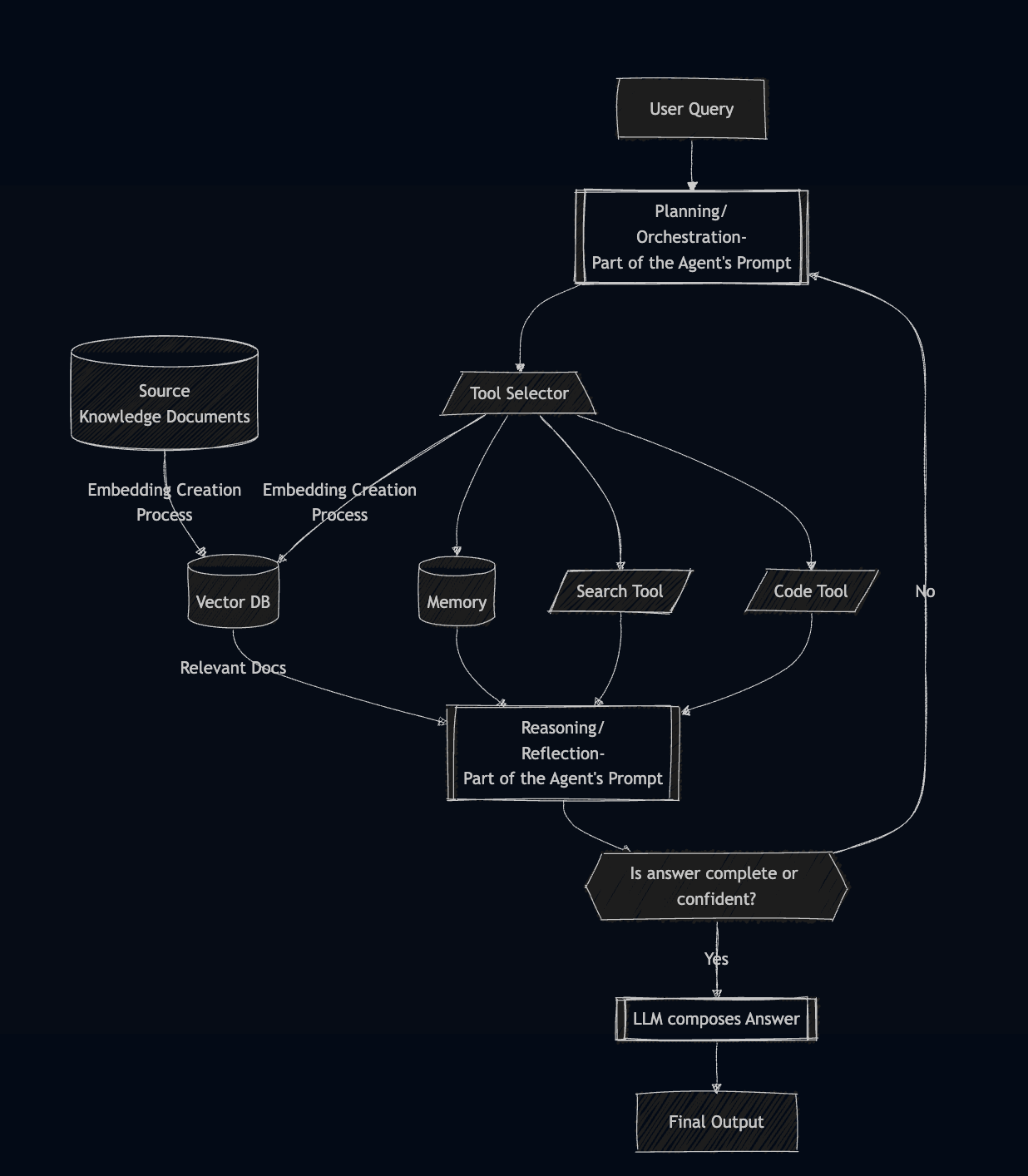
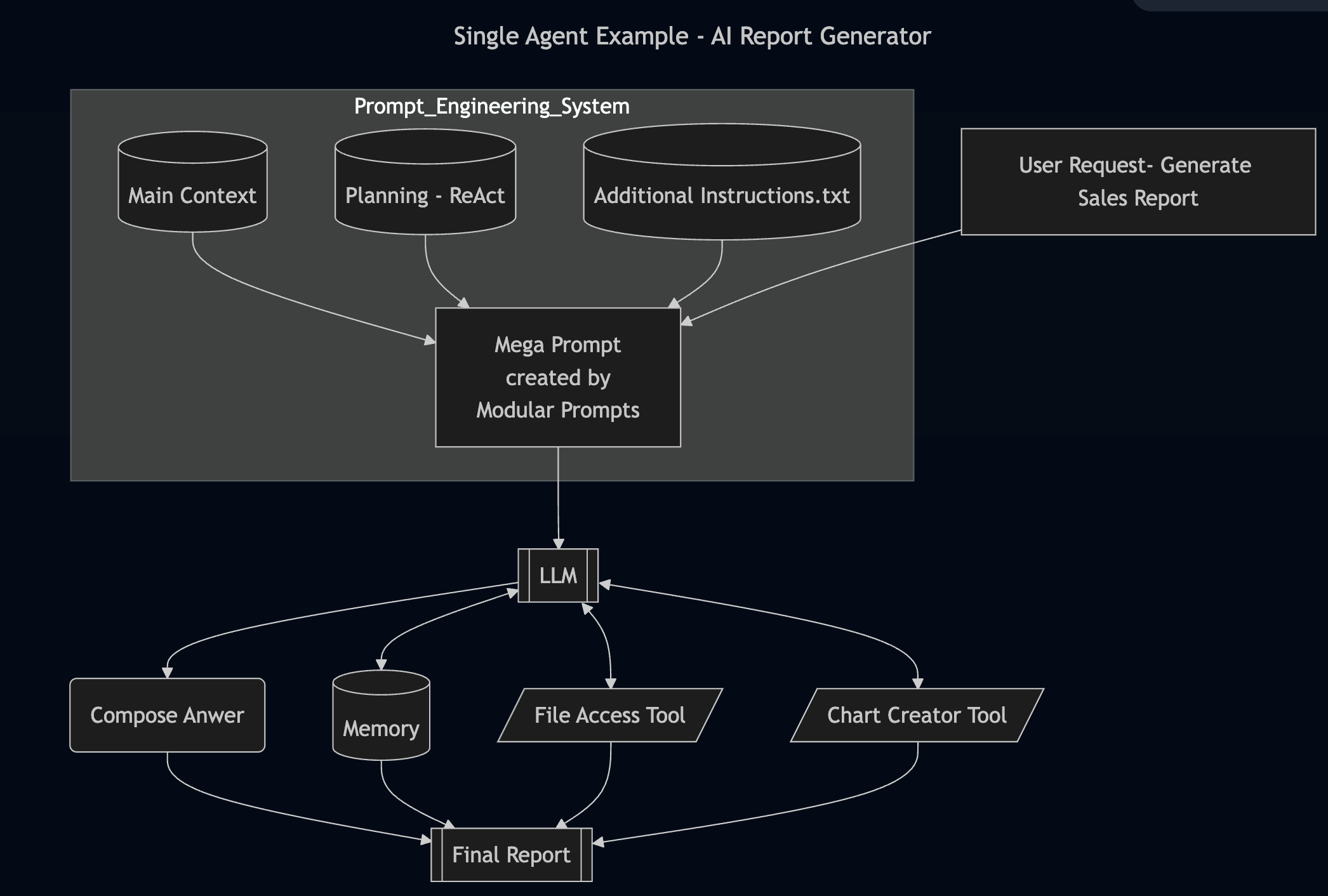
Architecture of a Single Agent
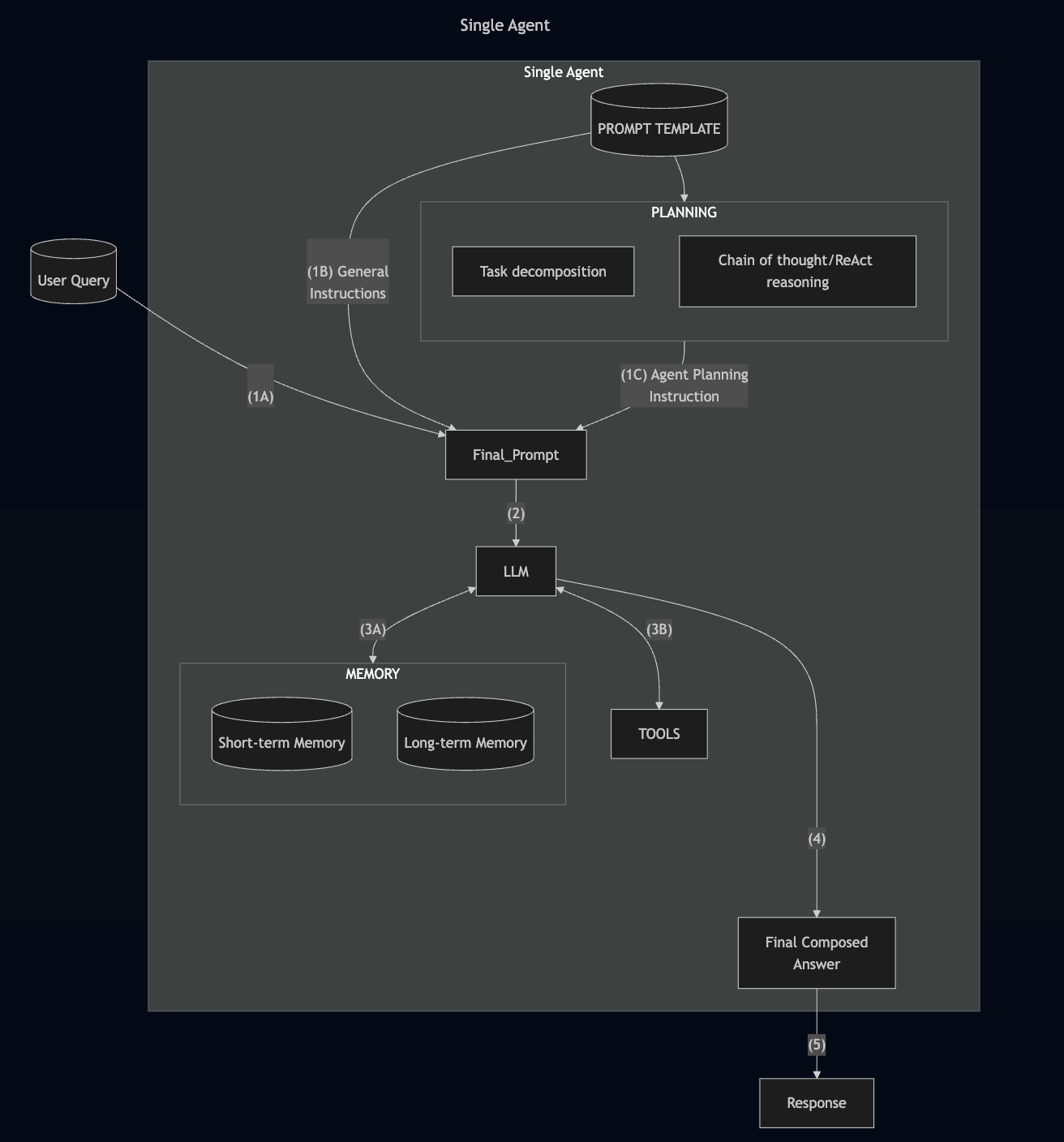
Example of a Single Agent Application
Agentic RAG
- Agentic RAG is not one-shot retrieval.
- The Agent retrieves, then reflects on the result, re-fetches if necessary
Where does MCP fit here?
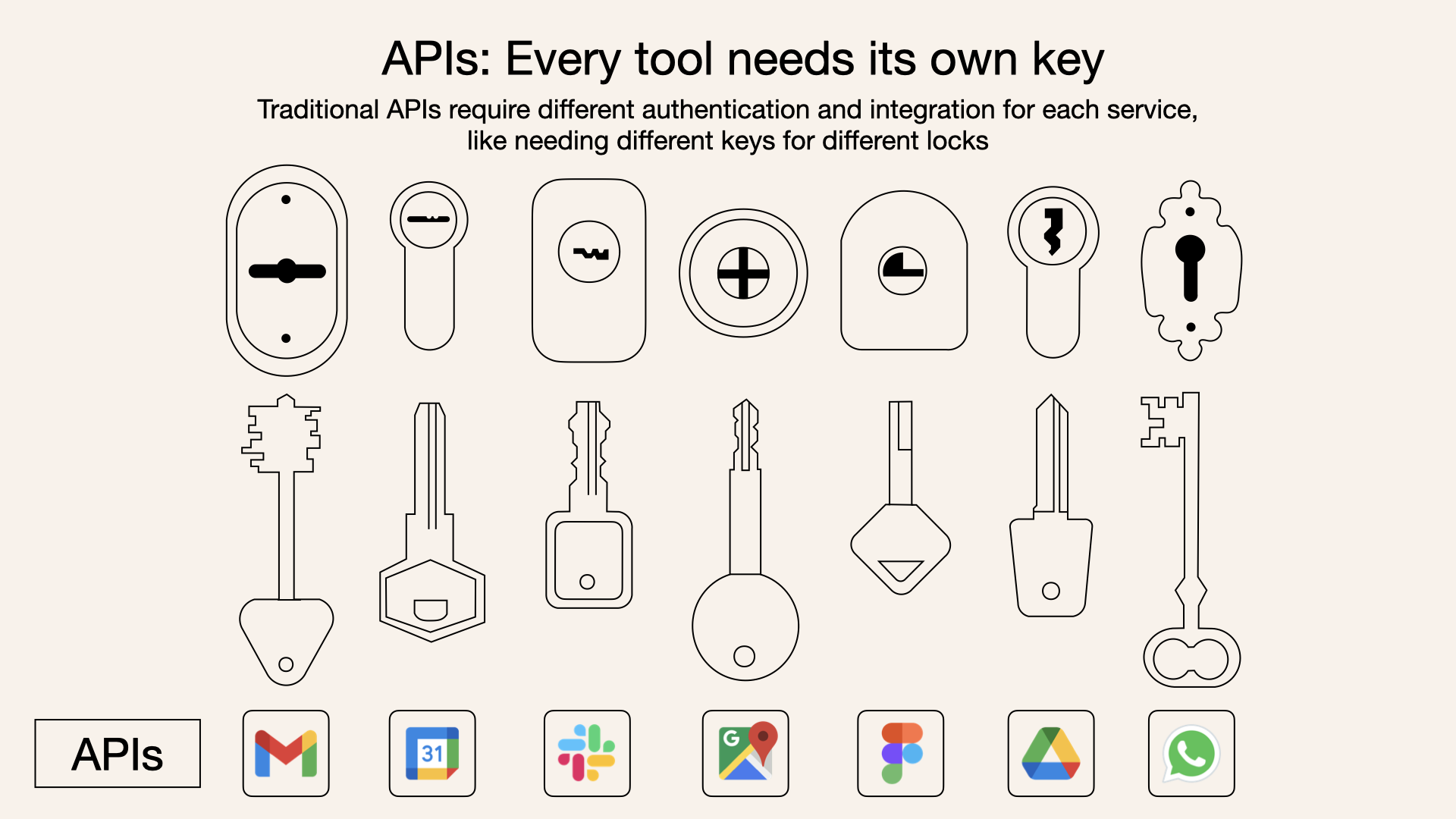
Before MCP:
After MCP:
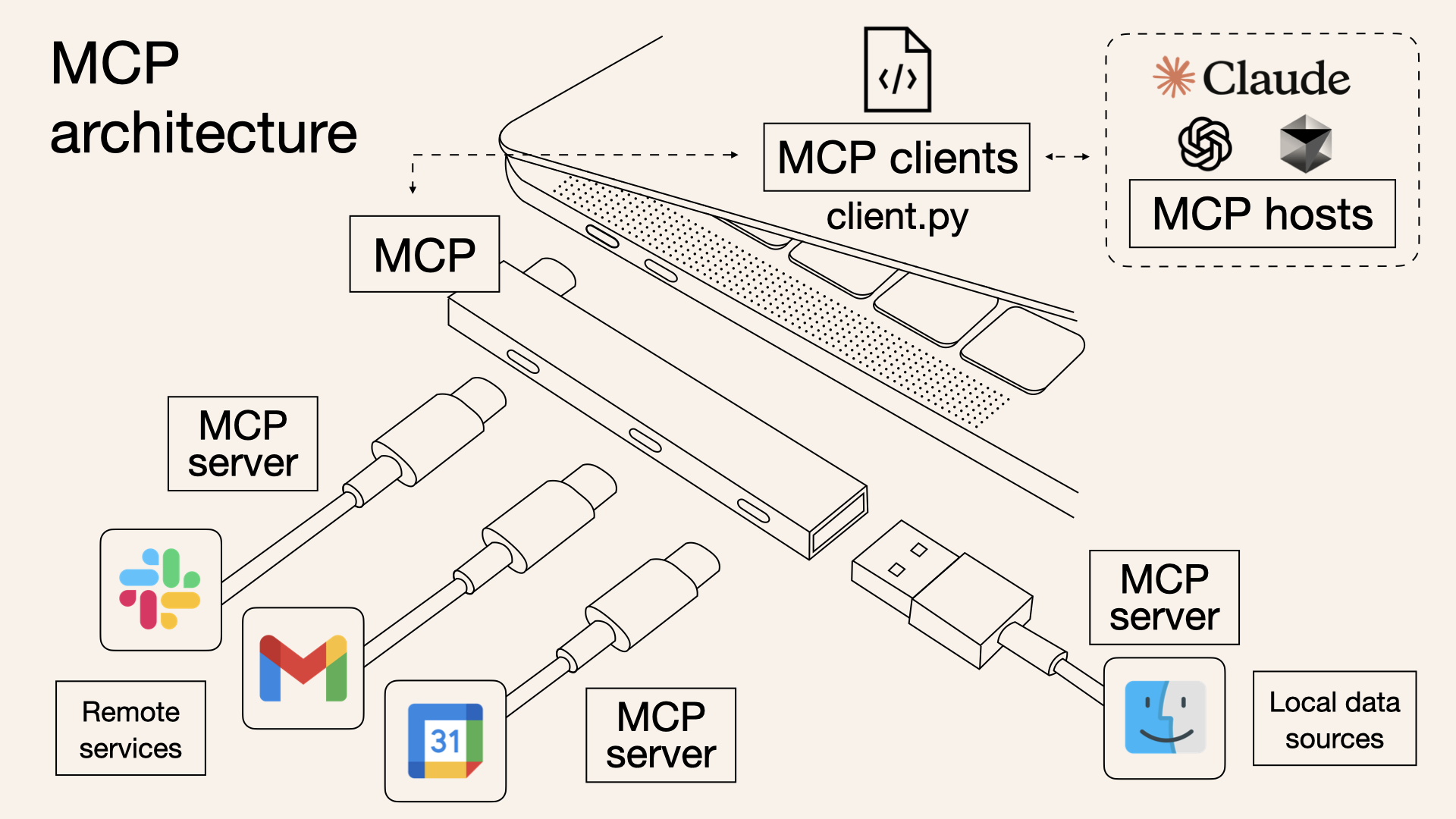
Source of the amazing images: Norah Sakal Blog Post
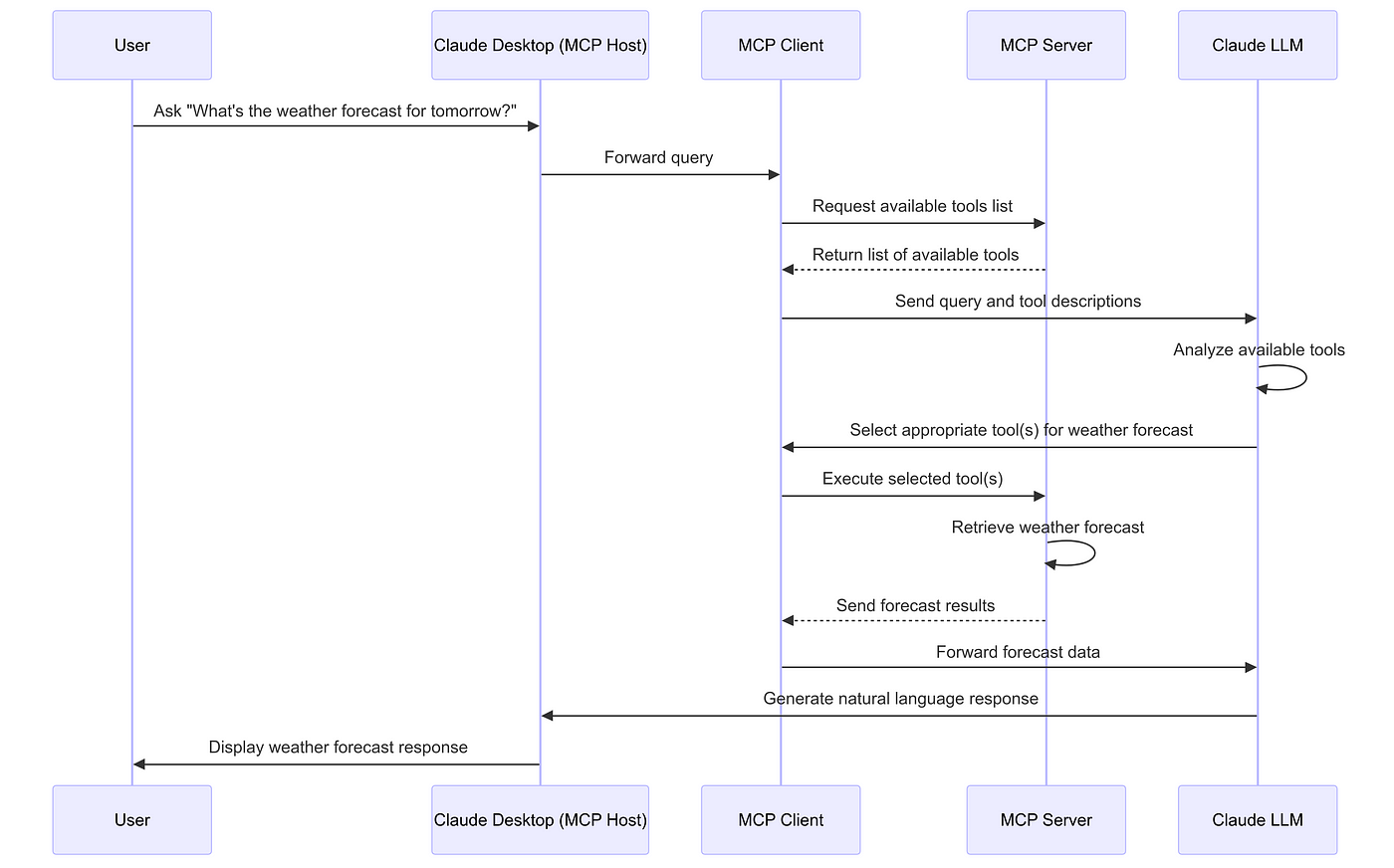
Where does MCP fit here?
- MCP - Not just a package or library (well it has a python package!).
- It is a protocol like TCP/SMTP. It is like OpenAPI Spec for REST APIs. source of the analogy
- MCP standardizes how the context (prompt, tools, memory, retrieved docs, etc.,) get passed on to the Model.
Source of the amazing image: Hirusha Fernando Medium Article
Multi-Agent Systems
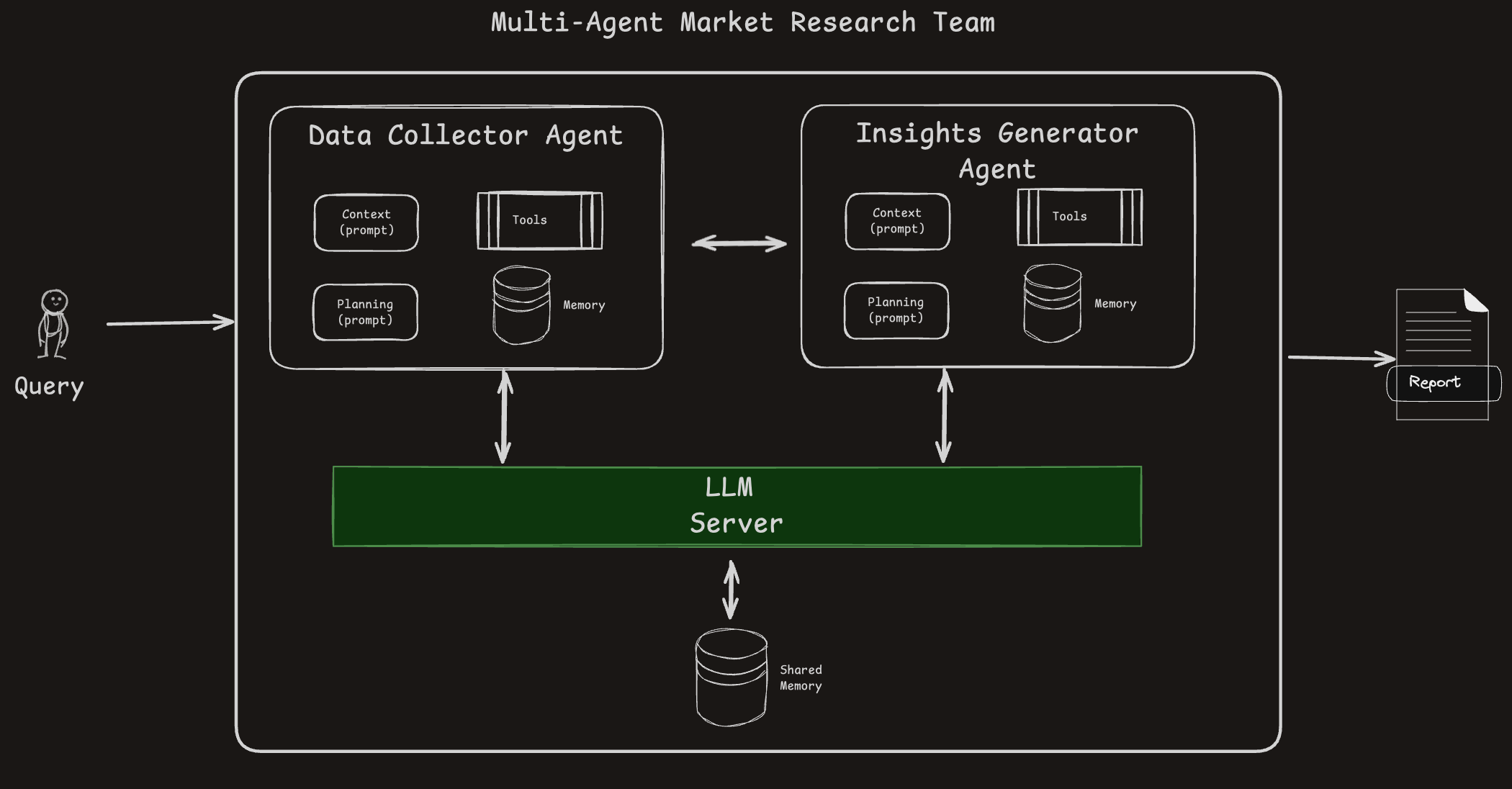
- Agents operate in parallel with their own responsibilities.
- Shared memory is used for cross-agent communication.
- Tool usage and autonomy allow scalable, modular problem-solving.