This blog post explains how to build Linear Text Classifiers using PyTorch’s modules such as nn.EmbeddingBag and nn.Embedding functions to convert tokenized text into embeddings
NLP
Coding
Author
Senthil Kumar
Published
September 15, 2021
1. Introduction
In this blog piece, let us cover how we can build a - text classification application using an embedding + fc layer
2.Representing Text as Tensors - A Quick Introduction
How do computers represent text? - Using encodings such as ASCII values to represent each character
Still computers cannot interpret the meaning of the words , they just represent text as ascii numbers in the above image
How is text converted into embeddings?
Two types of representations to convert text into numbers
Character-level representation
Word-level representation
Token or sub-word level representation
While Character-level and Word-level representations are self explanatory, Token-level representation is a combination of the above two approaches.
Some important terms:
Tokenization (sentence/text –> tokens): In the case sub-word level representations, for example, unfriendly will be tokenized as un, #friend, #ly where # indicates the token is a continuation of previous token.
This way of tokenization can make the model learnt/trained representations for friend and unfriendly to be closer to each other in the vector spacy
Numericalization (tokens –> numericals): This is the step where we convert tokens into integers.
Vectorization (numericals –> vectors): This is the process of creating vectors (typically sparse and equal to the length of the vocabulary of the corpus analyzed)
Embedding (numericals –> embeddings): For text data, embedding is a lower dimensional equivalent of a higher dimensional sparse vector. Embeddings are typically dense. Vectors are sparse.
Typical Process of Embedding Creation - text_data >> tokens >> numericals >> sparse vectors or dense embeddings
3. Difference between nn.EmbeddingBag vs nn.Embedding
nn.Embedding: A simple lookup table that looks up embeddings in a fixed dictionary and size.
nn.EmbeddingBag: Computes sums, means or maxes of bags of embeddings, without instantiating the intermediate embeddings.
Source: PyTorch Official Documentation
nn.Embedding Explanation: - In the above pic, we can see that the encoding of men write code being embedded as [(0.312,0.385), (0.543, 0.481), (0.203, 0.404)] where embed_dim=2. - Looking closer, men is embedded as (0.312,0.385) and the trailing <pad> token is embedded as (0.203, 0.404)
nn.EmbeddingBag Explanation: - In here, there is no padding token. The sentences in a batch are connnected together and saved with their offsets array - Instead of each word being represented by an embedding vector, each sentence is embedded into a embedding vector - This above process of “computing a single vector for an entire sentence” is possible also from nn.Embedding followed by torch.mean(dim=1) or torch.sum(dim=1) or torch.max(dim=1)
So, when to use nn.EmbeddingBag? - nn.EmbeddingBag works better when sequential information of words is not needed. - Hence can be used with simple Feed forward NN and not with LSTMs or Transformers (all the embedded words are sent at once and they are sequentially processed either from both directions or unidirectional)
Sources: - nn.EmbeddingBag vs nn.Embedding | link - nn.Emedding followed by torch.mean(dim=1) | link
4. A Text Classification Pipeline using nn.EmbeddingBag + nn.linear Layer
Dataset considered: AG_NEWS dataset that consists of 4 classes - World, Sports, Business and Sci/Tech
┣━━ 1.Loading dataset ┃ ┣━━ torch.data.utils.datasets.AG_NEWS ┣━━ 2.Load Tokenization ┃ ┣━━ torchtext.data.utils.get_tokenizer('basic_english') ┣━━ 3.Build vocabulary ┃ ┣━━ torchtext.vocab.build_vocab_from_iterator(train_iterator) ┣━━ 4.Create EmbeddingsBag ┃ ┣━━ Create collate_fn to create triplets of label-feature-offsets tensors for every minibatch ┣━━ 5.Create train, validation and test DataLoaders ┣━━ 6.Define Model_Architecture ┣━━ 7.define training_loop and testing_loop functions ┣━━ 8.Train the model and Evaluate on Test Data ┣━━ 9.Test the model on sample text
for label, text in random.sample(train_dataset, 3):print(label,classes[label-1])print(text)print("******")
1 World
EU-25 among least corrupt in global index Corruption is rampant in sixty countries of the world and the public sector continues to be plagued by bribery, says a report by a respected global corruption watchdog.
******
4 Sci/Tech
IDC Raises '04 PC Growth View, Trims '05 (Reuters) Reuters - Shipments of personal computers\this year will be higher than previously anticipated, boosted\by the strongest demand from businesses in five years, research\firm IDC said on Monday.
******
2 Sports
The not-so-great cover-up A crisis, they say, is the best way to test the efficiency of a system. At the Wankhede Stadium, there was a crisis on the first morning when unseasonal showers showed up on the first morning of the final Test.
******
4.4. Creating EmbeddingsBag related pipelines
The text pipeline purpose is to convert text into tokens
from torch import nnclass LinearTextClassifier(nn.Module):def__init__(self, vocab_size, embed_dim, num_class=4):super(LinearTextClassifier,self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True )# fully connected layerself.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self): initrange =0.5# initializing embedding weights as a uniform distributionself.embedding.weight.data.uniform_(-initrange, initrange)# initializing linear layer weights as a uniform distributionself.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, text, offsets): embedded =self.embedding(text, offsets)returnself.fc(embedded)
Initializing model and embedding dimension
num_classes =len(set([label for (label, text) in train_dataset]))
num_classes
4
vocab_size =len(vocab)embedding_dim =64# instantiating the class and pass on to devicemodel = LinearTextClassifier(vocab_size, embedding_dim, num_classes ).to(device)
# setting hyperparameterslr =3optimizer = torch.optim.SGD(model.parameters(), lr=lr)loss_fn = torch.nn.CrossEntropyLoss()epoch_size =10# setting a low number to see time consumption
def train_loop(model, train_dataloader, validation_dataloader, epoch, lr=lr, optimizer=optimizer, loss_fn=loss_fn, ): train_size =len(train_dataloader.dataset) validation_size =len(validation_dataloader.dataset) training_loss_per_epoch =0 validation_loss_per_epoch =0for batch_number, (labels, features, offsets) inenumerate(train_dataloader):if batch_number %100==0:print(f"In epoch {epoch}, training of {batch_number} batches are over")# following two lines are used while for testing if the fns are accurate# if batch_number %10 == 0:# break labels, features, offsets = labels.to(device), features.to(device), offsets.to(device)# labels = labels.clone().detach().requires_grad_(True).long().to(device) # compute prediction and prediction error pred = model(features, offsets)# print(pred.dtype, pred.shape) loss = loss_fn(pred, labels)# print(loss.dtype)# backpropagation steps# key optimizer steps# by default, gradients add up in PyTorch# we zero out in every iteration optimizer.zero_grad()# performs the gradient computation steps (across the DAG) loss.backward()# adjust the weights torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) optimizer.step() training_loss_per_epoch += loss.item()for batch_number, (labels, features, offsets) inenumerate(validation_dataloader): labels, features, offsets = labels.to(device), features.to(device), offsets.to(device)# labels = labels.clone().detach().requires_grad_(True).long().to(device)# compute prediction error pred = model(features, offsets) loss = loss_fn(pred, labels) validation_loss_per_epoch += loss.item() avg_training_loss = training_loss_per_epoch / train_size avg_validation_loss = validation_loss_per_epoch / validation_sizeprint(f"Average Training Loss of {epoch}: {avg_training_loss}")print(f"Average Validation Loss of {epoch}: {avg_validation_loss}")
def test_loop(model,test_dataloader, epoch, loss_fn=loss_fn): test_size =len(test_dataloader.dataset)# Failing to do eval can yield inconsistent inference results model.eval() test_loss_per_epoch, accuracy_per_epoch =0, 0# disabling gradient tracking while inferencewith torch.no_grad():for labels, features, offsets in test_dataloader: labels, features, offsets = labels.to(device), features.to(device), offsets.to(device)# labels = labels.clone().detach().requires_grad_(True).long().to(device)# labels = torch.tensor(labels, dtype=torch.float32) pred = model(features, offsets) loss = loss_fn(pred, labels) test_loss_per_epoch += loss.item() accuracy_per_epoch += (pred.argmax(1)==labels).type(torch.float).sum().item()# following two lines are used only while testing if the fns are accurate# print(f"Last Prediction \n 1. {pred}, \n 2.{pred.argmax()}, \n 3.{pred.argmax(1)}, \n 4.{pred.argmax(1)==labels}")# print(f"Last predicted label: \n {labels}")print(f"Average Test Loss of {epoch}: {test_loss_per_epoch/test_size}")print(f"Average Accuracy of {epoch}: {accuracy_per_epoch/test_size}")
4.8 Training the Model
# checking for 1 epoch, testing for 1 epochepoch =1train_loop(model, train_dataloader, valid_dataloader, epoch )test_loop(model, test_dataloader, epoch)
epoch_size
10
%%time# it takes time to run this modelfor epoch inrange(epoch_size):print(f"Epoch Number: {epoch}\n---------------------") train_loop(model, train_dataloader, valid_dataloader, epoch ) test_loop(model, test_dataloader, epoch)
Epoch Number: 0
---------------------
In epoch 0, training of 0 batches are over
In epoch 0, training of 100 batches are over
In epoch 0, training of 200 batches are over
In epoch 0, training of 300 batches are over
In epoch 0, training of 400 batches are over
In epoch 0, training of 500 batches are over
In epoch 0, training of 600 batches are over
In epoch 0, training of 700 batches are over
In epoch 0, training of 800 batches are over
In epoch 0, training of 900 batches are over
In epoch 0, training of 1000 batches are over
.....
In epoch 4, training of 28000 batches are over
In epoch 4, training of 28100 batches are over
In epoch 4, training of 28200 batches are over
In epoch 4, training of 28300 batches are over
In epoch 4, training of 28400 batches are over
Average Training Loss of 4: 0.06850743169194017
Average Validation Loss of 4: 0.10275975785597817
Average Test Loss of 4: 0.10988466973246012
Average Accuracy of 4: 0.9142105263157895
Epoch Number: 5
---------------------
In epoch 5, training of 0 batches are over
.....
In epoch 9, training of 28200 batches are over
In epoch 9, training of 28300 batches are over
In epoch 9, training of 28400 batches are over
Average Training Loss of 9: 0.05302847929670939
Average Validation Loss of 9: 0.12290485648680452
Average Test Loss of 9: 0.1306164133289306
Average Accuracy of 9: 0.9111842105263158
CPU times: user 5min 56s, sys: 25.8 s, total: 6min 22s
Wall time: 6min 13s
4.9.Test the model on sample text
ag_news_label = {1: "World",2: "Sports",3: "Business",4: "Sci/Tec"}def predict(text, model):with torch.no_grad(): tokenized_numericalized_vector = torch.tensor(_text_pipeline(text)) offsets = torch.tensor([0]) output = model(tokenized_numericalized_vector, offsets) output_label = ag_news_label[output.argmax(1).item() +1]return output_labelsample_string ="MEMPHIS, Tenn. – Four days ago, Jon Rahm was \ enduring the season’s worst weather conditions on Sunday at The \ Open on his way to a closing 75 at Royal Portrush, which \ considering the wind and the rain was a respectable showing. \ Thursday’s first round at the WGC-FedEx St. Jude Invitational \ was another story. With temperatures in the mid-80s and hardly any \ wind, the Spaniard was 13 strokes better in a flawless round. \ Thanks to his best putting performance on the PGA Tour, Rahm \ finished with an 8-under 62 for a three-stroke lead, which \ was even more impressive considering he’d never played the \ front nine at TPC Southwind."cpu_model = model.to("cpu")print(f"This is a {predict(sample_string, model=cpu_model)} news")
This is a Sports news
5. A Text Classification Pipeline using nn.Embedding + nn.linear Layer
Dataset considered: AG_NEWS dataset that consists of 4 classes - World, Sports, Business and Sci/Tech
(same architecture as previous one, except the change in step 4)
┣━━ 1.Loading dataset ┃ ┣━━ torch.data.utils.datasets.AG_NEWS ┣━━ 2.Load Tokenization ┃ ┣━━ torchtext.data.utils.get_tokenizer('basic_english') ┣━━ 3.Build vocabulary ┃ ┣━━ torchtext.vocab.build_vocab_from_iterator(train_iterator) ┣━━ 4.Create Embedding layer ┃ ┣━━ Create collate_fn (padify) to create pairs of label-feature tensors for every minibatch ┣━━ 5.Create train, validation and test DataLoaders ┣━━ 6.Define Model_Architecture ┣━━ 7.define training_loop and testing_loop functions ┣━━ 8.Train the model and Evaluate on Test Data ┣━━ 9.Test the model on sample text
Every data point in a text corpus could have different number of tokens
For maintaining uniform number of input tokens in texts, we padify the text
torch.nn.functional.pad on a tokenized dataset can padify the dataset
Source: Microsoft PyTorch Docs
def padify(batch):# batch is a list of (label, text) pair of tuples label_list, text_list = [], []for (_label, _text) in batch: label_list.append(_label_pipeline(_label)) tokenized_numericalized_text = torch.tensor(_text_pipeline(_text), dtype=torch.int64 ) text_list.append(tokenized_numericalized_text)# compute max length of a sequence in this minibatch max_length =max(map(len,text_list)) label_list_overall = torch.tensor(label_list, dtype=torch.int64 ) text_list_overall = torch.stack([torch.nn.functional.pad(torch.tensor(t), (0,max_length -len(t)), mode='constant', value=0) for t in text_list ])return label_list_overall.to(device), text_list_overall.to(device)
for i, (labels, features) inenumerate(test_dataloader):print(f"Tracking batch {i}")print(labels.shape)print(features.shape)if i ==3:breakprint("****")
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:18: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
from torch import nnclass LinearTextClassifier_2(nn.Module):def__init__(self, vocab_size, embed_dim, num_class=4):super(LinearTextClassifier_2,self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim, )# fully connected layerself.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self): initrange =0.5# initializing embedding weights as a uniform distributionself.embedding.weight.data.uniform_(-initrange, initrange)# initializing linear layer weights as a uniform distributionself.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()def forward(self, x): x =self.embedding(x) x = torch.mean(x, dim=1)returnself.fc(x)
Initializing the model hyperaparameters
num_classes =len(set([label for (label, text) in train_dataset]))
vocab_size =len(vocab)embedding_dim =64# instantiating the class and pass on to devicemodel_2 = LinearTextClassifier_2(vocab_size, embedding_dim, num_classes ).to(device)
# setting hyperparameterslr =0.001optimizer = torch.optim.Adam(model_2.parameters(), lr=lr)loss_fn = torch.nn.CrossEntropyLoss()epoch_size =3# setting a low number to see time consumption
5.7. Define train_loop and test_loop functions
def train_loop_2(model_2, train_dataloader, validation_dataloader, epoch, lr=lr, optimizer=optimizer, loss_fn=loss_fn, ): train_size =len(train_dataloader.dataset) validation_size =len(validation_dataloader.dataset) training_loss_per_epoch =0 validation_loss_per_epoch =0for batch_number, (labels, features) inenumerate(train_dataloader):if batch_number %1000==0:print(f"In epoch {epoch}, training of {batch_number} batches are over")# following two lines are used while for testing if the fns are accurate# if batch_number %10 == 0:# break labels, features = labels.to(device), features.to(device)# labels = labels.clone().detach().requires_grad_(True).long().to(device) # compute prediction and prediction error pred = model_2(features)# print(pred.dtype, pred.shape) loss = loss_fn(pred, labels)# print(loss.dtype)# backpropagation steps# key optimizer steps# by default, gradients add up in PyTorch# we zero out in every iteration optimizer.zero_grad()# performs the gradient computation steps (across the DAG) loss.backward()# adjust the weights# torch.nn.utils.clip_grad_norm_(model_2.parameters(), 0.1) optimizer.step() training_loss_per_epoch += loss.item()for batch_number, (labels, features) inenumerate(validation_dataloader): labels, features = labels.to(device), features.to(device)# labels = labels.clone().detach().requires_grad_(True).long().to(device)# compute prediction error pred = model_2(features) loss = loss_fn(pred, labels) validation_loss_per_epoch += loss.item() avg_training_loss = training_loss_per_epoch / train_size avg_validation_loss = validation_loss_per_epoch / validation_sizeprint(f"Average Training Loss of {epoch}: {avg_training_loss}")print(f"Average Validation Loss of {epoch}: {avg_validation_loss}")
def test_loop_2(model_2,test_dataloader, epoch, loss_fn=loss_fn): test_size =len(test_dataloader.dataset)# Failing to do eval can yield inconsistent inference results model_2.eval() test_loss_per_epoch, accuracy_per_epoch =0, 0# disabling gradient tracking while inferencewith torch.no_grad():for labels, features in test_dataloader: labels, features = labels.to(device), features.to(device)# labels = labels.clone().detach().requires_grad_(True).long().to(device)# labels = torch.tensor(labels, dtype=torch.float32) pred = model_2(features) loss = loss_fn(pred, labels) test_loss_per_epoch += loss.item() accuracy_per_epoch += (pred.argmax(1)==labels).type(torch.float).sum().item()# following two lines are used only while testing if the fns are accurate# print(f"Last Prediction \n 1. {pred}, \n 2.{pred.argmax()}, \n 3.{pred.argmax(1)}, \n 4.{pred.argmax(1)==labels}")# print(f"Last predicted label: \n {labels}")print(f"Average Test Loss of {epoch}: {test_loss_per_epoch/test_size}")print(f"Average Accuracy of {epoch}: {accuracy_per_epoch/test_size}")
5.8 Training the model
# checking for 1 epoch, testing for 1 epochepoch =1train_loop_2(model_2, train_dataloader, valid_dataloader, epoch )test_loop_2(model_2, test_dataloader, epoch)
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:18: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
In epoch 1, training of 0 batches are over
In epoch 1, training of 1000 batches are over
In epoch 1, training of 2000 batches are over
In epoch 1, training of 3000 batches are over
.....
In epoch 1, training of 26000 batches are over
In epoch 1, training of 27000 batches are over
In epoch 1, training of 28000 batches are over
Average Training Loss of 1: 0.08683817907764081
Average Validation Loss of 1: 0.0605684169218495
Average Test Loss of 1: 0.06346218769094585
Average Accuracy of 1: 0.9201315789473684
Code
# it takes time to run this modelfor epoch inrange(epoch_size):print(f"Epoch Number: {epoch}\n---------------------") train_loop_2(model_2, train_dataloader, valid_dataloader, epoch ) test_loop_2(model_2, test_dataloader, epoch)
5.9. Test the model on sample text
ag_news_label = {1: "World",2: "Sports",3: "Business",4: "Sci/Tec"}def predict_2(text, model): batch = [(torch.tensor([0]), text ) ]with torch.no_grad(): _, padded_sequence = padify(batch) padded_sequence = padded_sequence.to("cpu")# tokenized_numericalized_vector = torch.tensor(_text_pipeline(text)) output = model_2(padded_sequence) output_label = ag_news_label[output.argmax(1).item() +1]return output_labelsample_string ="MEMPHIS, Tenn. – Four days ago, Jon Rahm was \ enduring the season’s worst weather conditions on Sunday at The \ Open on his way to a closing 75 at Royal Portrush, which \ considering the wind and the rain was a respectable showing. \ Thursday’s first round at the WGC-FedEx St. Jude Invitational \ was another story. With temperatures in the mid-80s and hardly any \ wind, the Spaniard was 13 strokes better in a flawless round. \ Thanks to his best putting performance on the PGA Tour, Rahm \ finished with an 8-under 62 for a three-stroke lead, which \ was even more impressive considering he’d never played the \ front nine at TPC Southwind."cpu_model_2 = model_2.to("cpu")print(f"This is a {predict_2(sample_string, model=cpu_model_2)} news")
This is a Sports news
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:18: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
6. Conclusion
In this blog piece, we looked at how we can build linear classifiers (without non-linear activation functions) over nn.EmbeddingBag and nn.Embedding modules
In the nn.EmbeddingBag method of embedding creation, we did not create padding tokens but have to track offsets for every minibatch.
In the nn.Embedding method of creating embeddings, we used torch.nn.functional.pad function to ensure all text sequences have fixed length


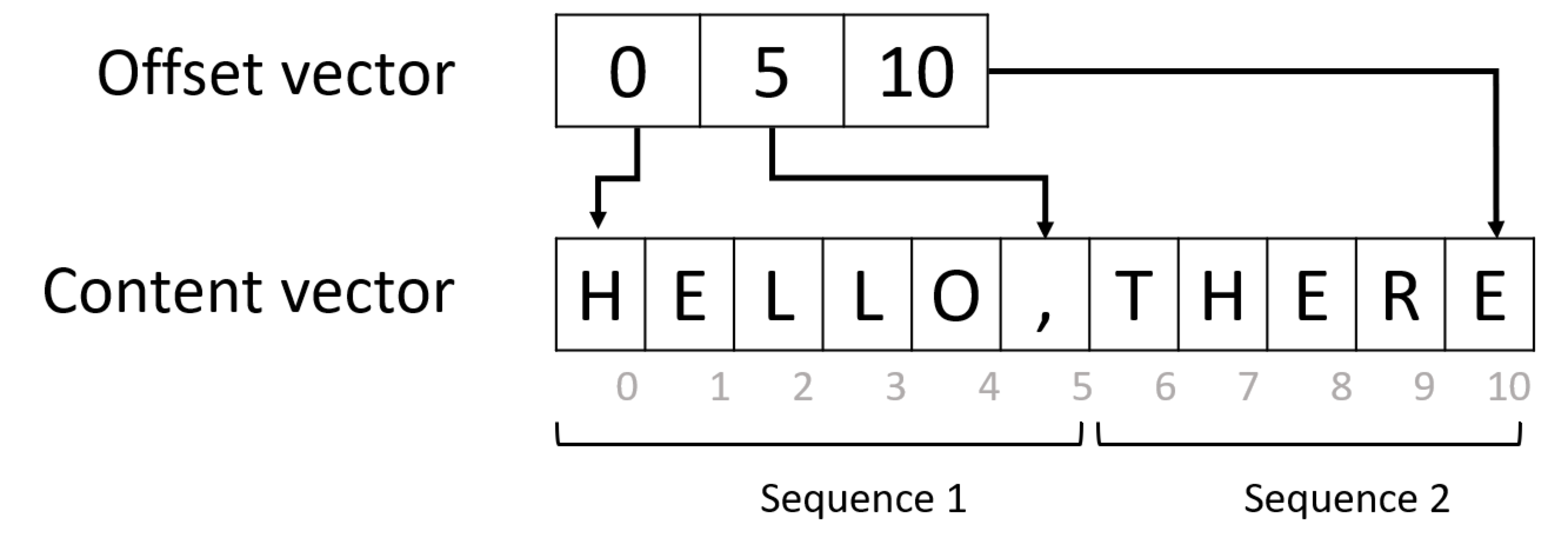
 Source: Microsoft PyTorch Docs
Source: Microsoft PyTorch Docs